Démystifier le Machine Learning Expliquer de manière simple et accessible ce qu’est le Machine Learning, ses concepts fondamentaux, et comment il fonctionne dans la pratique.
Présenter les applications concrètes Montrer comment le Machine Learning est utilisé dans la vie quotidienne et dans différents secteurs professionnels, pour que le lecteur comprenne son impact réel.
Sensibiliser aux limites et défis Identifier les contraintes, limites et défis éthiques du Machine Learning afin que les lecteurs développent une compréhension critique de l’IA.
Proposer un regard original sur l’IA Offrir une approche différente de l’IA, qui va au-delà de la théorie pour inclure des perspectives pratiques, stratégiques et pédagogiques.
Fournir des ressources fiables Mettre à disposition des références, documents et sources pédagogiques pour que les lecteurs puissent approfondir leurs connaissances.
Inspirer la curiosité et l’expérimentation Encourager les lecteurs à explorer le Machine Learning par eux-mêmes, à tester des modèles et à réfléchir aux innovations possibles dans ce domaine.
Tout a réellement commencé dans les années 1950, avec un homme nommé Arthur Samuel. Cet ingénieur chez IBM a eu une idée révolutionnaire : et si une machine pouvait apprendre d’elle-même à partir de son expérience, un peu comme un humain ? Pour le prouver, il a programmé un ordinateur (1959) capable de jouer aux dames. Au fil des parties, l’ordinateur s’améliorait sans qu’on doive le reprogrammer manuellement. Il observait ses erreurs, retenait ses bons coups, et devenait plus fort. C’était la naissance d’un nouveau concept : , ou en anglais.
l’apprentissage automatique
machine learning
Machines jouant au échec
À l’époque, ce n’était qu’une curiosité scientifique. Mais aujourd’hui, ce principe est au cœur de presque tout ce qui nous entoure :
Quand Netflix te recommande un film,
Quand Google complète ta recherche avant même que tu finisses de taper,
Quand ton téléphone reconnaît ton visage, c’est le machine learning qui agit discrètement en arrière-plan.
Initialement, lorsqu'on veut résoudre un problème en informatique par exemple, on a tendance à écrire un algorithme pour le résoudre (Faire le tri, Recherche, calculs, etc...). Toutefois, il existe des problèmes où écrire un algorithme serait trop complexe voir impossible (le problème du voyageur de commerce, le problème de la satisfiabilité booléenne, reconnaitre des images, sons, etc...).
Lemachine learning (ou apprentissage automatique) est une branche de l’intelligence artificielle (IA). L’idée est simple : au lieu de programmer explicitement une solution, on apprend à la machine à trouver elle-même la solution à partir des données (les données ici correspondent au dataset ou jeu de données mais nous y reviendrons).
Prenons un exemple concret : Tu veux qu’un ordinateur reconnaisse les photos de chats. Au lieu d’écrire des lignes de code du genre “si l’image a des moustaches et des oreilles pointues, alors c’est un chat”, tu lui montres des milliers d’images de chats et de non-chats. Avec le temps, la machine trouve seule les différences et déduit ses propres règles. On parlera alors de modèle, qu'elle ajuste afin d'être performante.
Ainsi machine learning consiste à donner des exemples à une machine pour qu’elle apprenne des modèles et fasse ensuite des prédictions ou des décisions sans être programmée ligne par ligne.
Parce que nous vivons dans une ère où les données sont partout : photos, vidéos, capteurs, messages, clics, positions GPS, etc. Aucune personne humaine ne pourrait analyser tout cela à la main.
Le machine learning permet de :
Découvrir des tendances cachées dans des millions de données ;
Automatiser des tâches complexes comme la traduction ou la reconnaissance vocale ;
Prendre des décisions plus rapides et souvent plus précises que les humains ;
Créer des innovations dans la santé, les transports, la finance, et même l’éducation.
En clair, c’est ce qui transforme l’intelligence artificielle d’un simple rêve en outil concret et utile dans notre quotidien.
Apprendre, pour une machine, c’est un peu comme pour nous : elle observe, fait des essais, se trompe, corrige et recommence. Mais selon le type d’apprentissage, la manière dont elle reçoit les informations et les corrige varie. En général, on distingue trois grandes familles d’apprentissage machine :
Dans ce type d’apprentissage, la machine apprend à partir d’exemples déjà “corrigés”. C’est un peu comme un élève à qui le professeur donne les bonnes réponses pour s’entraîner.
Apprentissage à l'école supervisé par le professeur
L’ordinateur reçoit donc :
Les données d’entrée (par exemple : la photo d’un animal), qu'on appelle attributs, features ou observations
Et la bonne réponse associée (par exemple : “c’est un chat”). qu'on appelle étiquettes ou labels
L’objectif est que, plus tard, la machine puisse deviner la bonne réponse toute seule pour de nouvelles données qu’elle n’a jamais vues.
On distingue deux grandes catégories d'apprentissage supervisé : la classification et la régression.
C’est le cas où la machine doit choisir entre plusieurs catégories. Le But est depermettre à la machine de classer les données dans la bonne catégorie.
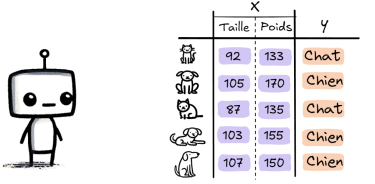
Dans le cas où tu veux qu’un programme reconnaisse s’il s’agit d’un chat ou d’un chien à partir d'information sur leur poids et taille. Tu lui donnes des centaines de données (Taille , Poids) , avec leur étiquette (“chat” ou “chien”).
X: features Y: étiquettes
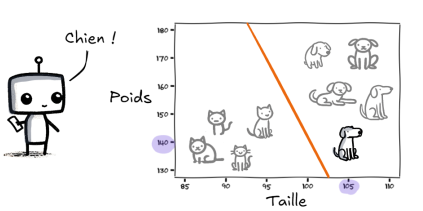
Au fil du temps, il apprend à associer des informations (Taille , Poids) à un des deux animaux afin de distinguer un chat d’un chien tout seul.
Distinction chien et chat
Ainsi, pour une nouvel animal dont il n'a jamais eu les informations (Taille , Poids) qu'on lui présente;
Nouvel Animal
Il pourra être capable de le reconnaitre à travers un modèle qu'il a ajusté lui même afin de faire le distinguo.
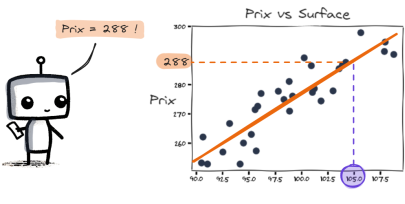
Ici, la machine ne cherche pas une catégorie, mais une valeur numérique. Son objectif est de de prédire des valeurs continues, comme un prix, une température, ou une durée.
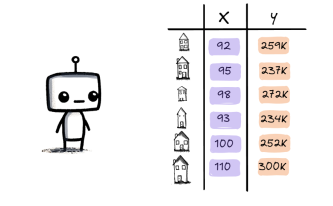
Prenons le cas où l'on souhaite prédire le prix d’une maison selon sa superficie. On montre à la machine des centaines d’exemples (surface => prix).
Donnée surface associer à un prix - X: features Y: étiquettes
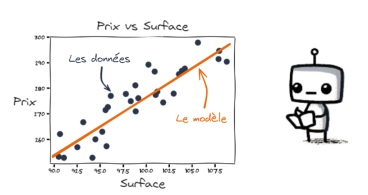
Elle apprend à trouver la relation mathématique entre les deux : plus la maison est grande, plus le prix augmente. Et les matheux, comprendront qu'il pourrait s'agir ici d'une droite croissante.
Ajustement par une relation mathématique d'un prix et une surface
la machine essaiera d'ajuster la droite de manière à ce que les données correspondent le mieux. Sachez par ailleurs, qu'il existe des algorithme qui permet de trouver le meilleur ajustement pour la droite: on parlera alors d'optimisation.
Ainsi, pour une nouvel valeur de superficie correspondant à une nouvelle maison,
Nouvel Maison
la machine essaiera de prédire son prix en utilisant le modèle obtenu à partir des données qu'il a eu.
Cette fois, la machine n’a pas les bonnes réponses à l’avance. Elle reçoit seulement les données, et doit découvrir seule comment elles s’organisent.
C’est comme si on te donnait une pile de photos d’animaux sans te dire lesquels sont des chats ou des chiens. Tu essaierais naturellement de les regrouper par ressemblance.
C’est la méthode la plus utilisée dans l’apprentissage non supervisé. Le mot “cluster” signifie “groupe” ou “amas”. L’ordinateur cherche à regrouper les éléments qui se ressemblent.
Exemple concret : On donne à la machine des centaines de photos d’animaux sans nom.
Données sur animaux sans étiquettes
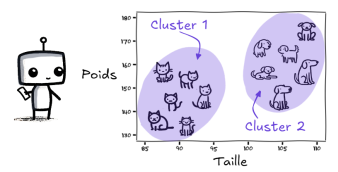
Elle va les analyser et former deux groupes naturels :
Groupe 1 : animaux avec oreilles pointues, museau court => chats ;
Groupe 2 : animaux avec museau long, oreilles tombantes => chiens.
Groupement en cluster
Les groupes ici correspondent à des clusters, qui permettent à la machine de différencier selon les critères mentionnés plus haut. Il est important de noter ici que la machine aurait pu regrouper selon d'autres critères comme les sexes des animaux,, leur tailles ou alors leur odeurs. Et les clusters seraient constitués autrement.
Le But est dedécouvrir des structures cachées dans les données sans avoir besoin d’étiquettes.
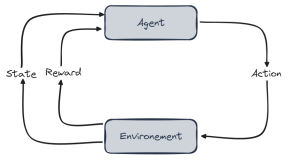
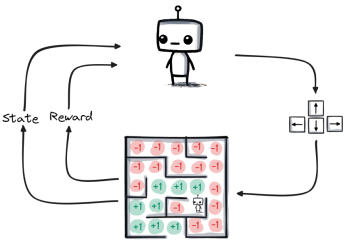
Ici, la machine apprend par essais et erreurs, comme un enfant qui apprend à faire du vélo. Chaque fois qu’elle agit, elle reçoit une récompense ou une punition, et adapte son comportement pour maximiser sa “récompense”.
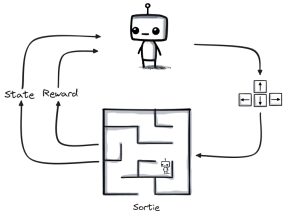
Imagine un robot dans un labyrinthe. Au début, il avance au hasard, se cogne souvent et prend de mauvaises directions. Mais à force d’essais, il mémorise les bons chemins et finit par trouver la sortie rapidement, sans erreur.
Apprentissage dans un labyrinthe
Le but rechercher est permettre à la machine de prendre les meilleures décisions possibles dans un environnement changeant. Vous pouvez cliquer sur Jeu du monde du Wumpus pour voir un autre exemple d'apprentissage par renforment d'un agent.
Avant qu’une machine puisse “comprendre” ou “prédire”, elle doit passer par un cycle d’apprentissage. Ce cycle ressemble beaucoup à une méthode scientifique : on observe, on apprend, on teste, puis on corrige.
Tout commence par les données. Ce sont elles qui alimentent la machine. Elles peuvent venir de photos, de sons, de textes, de capteurs, ou encore de transactions en ligne. La qualité de ces données est primordiale : des données mal préparées donnent un mauvais apprentissage.
Les données sont souvent brutes, incomplètes ou désordonnées. On doit donc les nettoyer, supprimer les doublons, corriger les erreurs, et parfois les transformer en nombres pour que la machine puisse les comprendre.
Les deux premières méthodes permettent de constitué un jeu de données ou dataset comme mentionné plus haut. Cliquer sur comment créer un dataset, un article de Bounyamine Ousmanou pour en savoir d'avantage.
C’est la phase la plus importante. La machine analyse les exemples et cherche les relations cachées dans les données. Elle ajuste peu à peu ses “paramètres internes” pour réduire ses erreurs. On appelle ce processus l’entraînement.
Une fois entraîné, le modèle est testé sur de nouvelles données qu’il n’a jamais vues. Cela permet de vérifier s’il a vraiment compris, ou s’il s’est simplement “souvenu” des exemples d’entraînement.
Si le modèle fonctionne bien, on peut l’utiliser dans des applications réelles (santé, finance, transport…). Sinon, on reprend le cycle : on ajoute plus de données, on ajuste les paramètres, et on recommence.
En résumé, une machine apprend par essais successifs, et chaque cycle la rend plus précise.
Les algorithmes analysent des milliers d’images médicales pour détecter des tumeurs, prédire des maladies, ou aider au diagnostic. Ils assistent les médecins, sans jamais les remplacer, pour gagner du temps et améliorer la précision.
Les plateformes d’apprentissage en ligne utilisent le machine learning pour adapter les cours à chaque élève. Si un étudiant a du mal avec un concept, le système lui propose automatiquement des exercices ciblés. C’est une forme de pédagogie personnalisée rendue possible par l’IA.
Ordinateur interactif pour apprentissage en milieu éducatif
Les voitures autonomes, les applications GPS et même les systèmes de gestion du trafic s’appuient sur le machine learning pour analyser les routes, anticiper les dangers et optimiser les trajets. Chaque seconde, des millions de données sont traitées pour rendre la conduite plus sûre et plus fluide.
Les banques utilisent le machine learning pour détecter les fraudes, analyser les risques et prédire les tendances du marché. Les sites de commerce en ligne, eux, s’en servent pour recommander des produits selon nos goûts et nos habitudes.
Grâce à des capteurs et à des images satellites, les algorithmes peuvent prévoir les rendements agricoles, détecter la sécheresse, ou encore optimiser l’arrosage. Le machine learning aide ainsi à protéger les ressources naturelles et à mieux gérer la planète.
Une machine ne sait apprendre que si elle a beaucoup de données, et surtout de bonnes données. Si les informations sont fausses ou incomplètes, le modèle prendra de mauvaises décisions.
Certains modèles sont si complexes qu’on ne sait plus comment ils prennent leurs décisions. C’est ce qu’on appelle le problème de la “boîte noire”. Dans certains domaines (comme la justice ou la santé), cette opacité peut être dangereuse.
Si les données d’apprentissage contiennent des préjugés humains, la machine les reproduira. Par exemple, un modèle mal entraîné pourrait discriminer certains profils sans le vouloir.
Le machine learning n’est pas une magie, mais une science de l’observation et de l’adaptation. Il apprend du passé pour prédire l’avenir, et il évolue à chaque instant grâce aux données que nous produisons. Il transforme nos vies dans presque tous les domaines : santé, éducation, mobilité, agriculture, et bien plus.
Mais il faut garder en tête qu’une machine ne “pense” pas. Elle calcule, apprend, mais ne comprend pas. C’est à nous, humains, d’en faire un usage éthique, intelligent et responsable.
Claude Mythos, le modèle d'Anthropic dédié à la cybersécurité, redessine les rapports de force numériques. Architecture, enjeux et controverses expliqués.
Claude MythosProject GlasswingAnthropicAI Securityvulnérabilités zero-day IA